The following section was written on 2023-08-05.
Introduction
For me, learning is all about getting your hands dirty. I’ve been looking at Mesa source code lately (and have already made one contribution thus far!), and I’ve found another issue to tackle:
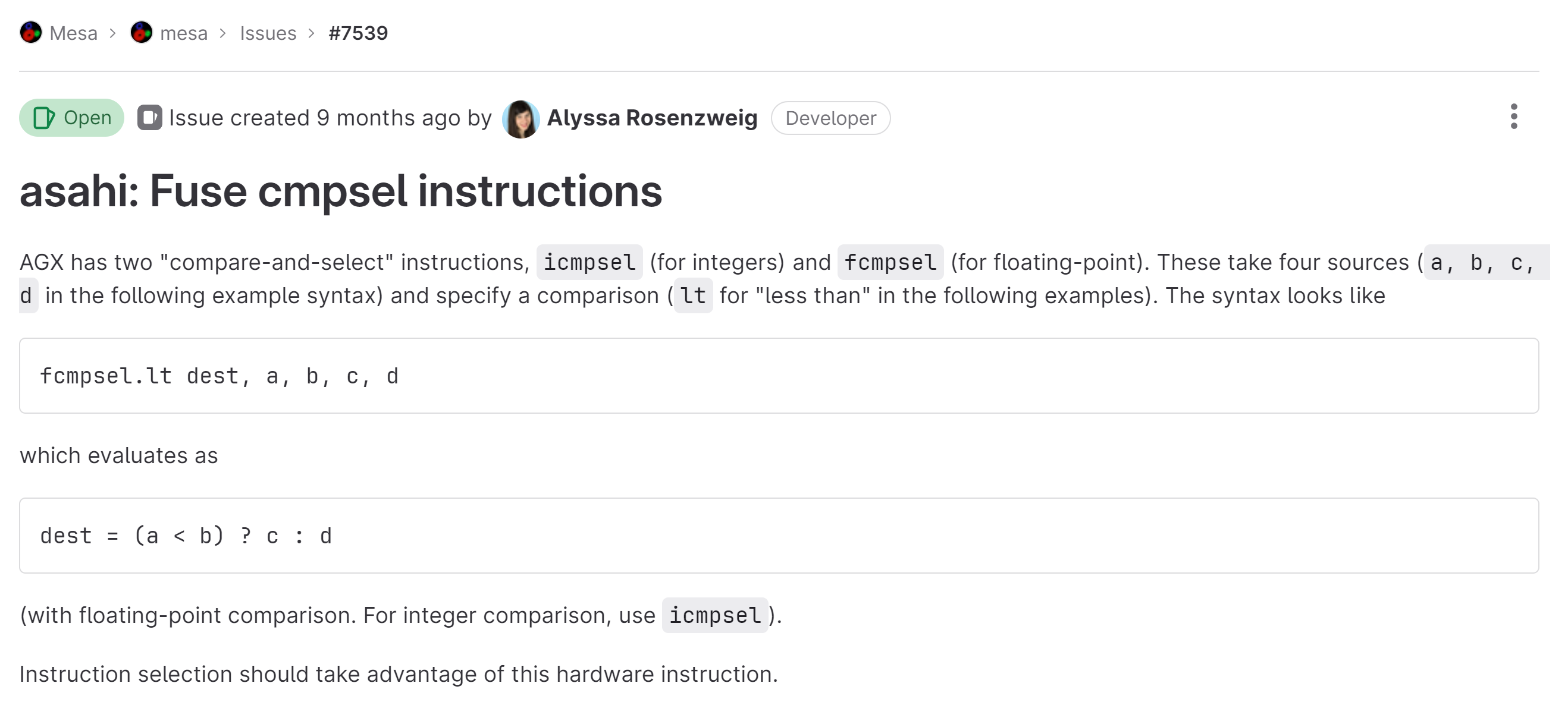
So we have our background, AGX (Apple’s GPU) has an instruction, fcmpsel (and its integer counterpart, icmpsel), which essentially perform cmp(a, b) ? c : d. If you want more information about these instructions,
dougallj’s docs are an excellent resource.
Reading on:

Here states the issue: NIR does not have an equivalent to AGX fcmpsel, so it eventually turns into two cmpsel instructions. Obviously, this is suboptimal: It increases code size and it misses some small performance gains in shaders.
I’m going to skip forward a bit here (but you should definitely read the issue itself! It’s really quite well-written and is telling of how shader compilers optimize register usage), but at the end the issue it states the possible heuristics we can select to fix this issue:

This may seem roundabout: Why are there different heuristics being suggested? Isn’t this just a simple case the optimizer can merge? Well, the issue is that those two emitted cmpsels may be far apart, so we need to be aware of our usage of registers when ordering instructions.
Understanding register pressure
To understand why register usage matters, we first need to understand how GPUs execute shaders.
It goes without saying, but GPUs are highly parallel processors, with really only one job: Process as much data as possible, as fast as possible. The processing that is involved with that data is what our shaders are, and those shaders are fairly dumb. The (very) wide SIMD units in each compute unit (or SM in Nvidia terms) are simplistic as far as modern processing goes, lacking any of the fancy machinery that, say, the CPU has. So then, it should be clear that the data we process should be done in chunks that can fit on each compute unit. Those chunks of work are called “waves” (or warps, again in Nvidia terms).
Shaders almost always need to access some varying data elsewhere (that is, data that varies for each “slice” of the SIMD, not uniform data that can live rent-free in the SGPR). That data tends to be far away from the compute unit, e.g., a sampled image or a storage buffer. Even though we can do as much as possible to leverage caching and minimize latency of such accesses, such as using tiled image memory layouts so that cache fetches are spatially localized, there will always be some latency with moving that memory to the compute unit. The next best thing that can be done is to hide the latency by doing something else productive instead of idling. What we could do is run multiple waves on a single compute unit, scheduled so that once we hit a memory fetch on one wave, we swap out to another wave to start processing in the meantime. The number of waves we can assign to one compute unit is called occupancy and the level of occupancy primarily depends upon how much register space we have.
If we don’t have much register space - or conversely, each wave (shader invocation) takes up a lot register space (this is called register pressure) - our occupancy won’t be great. There are two options to deal with this:
- Either sacrifice occupancy and move on
- Or, “spill” the registers for higher occupancy
Each option has its own costs which is why having high occupancy is not always a good thing. To “spill” the registers is to temporarily store some registers elsewhere (CU local memory) so that at any given snapshot in time, the wave is using less registers and therefore more waves can run concurrently on each compute unit. However, loading registers to/from local memory is not free and also has some performance penalty. Thus, it’s really about striking a balance between good occupancy so the GPU always has something to do, but also not spilling so many registers that the GPU spends a lot of time loading registers back from local memory.
Hopefully that explains why minimizing shader register usage is so important. If we can avoid using registers without even spilling, it’s the most ideal situation to be in. In our case, how we merge those two cmpsel instructions in certain cases could affect how long we hold onto some registers.
Putting it together
Now that we understand the problem, we should solve it. Alyssa has kindly listed the tasks that need to be done for this issue:

Unit testing
Getting on with it, let’s head into test-optimizer.cpp to write some test cases for this particular AGX sequence. Looking at an existing test to get a rough idea of what my test should look like:
TEST_F(Optimizer, FusedFnegCancel)
{
CASE32(agx_fmul_to(b, out, wx, agx_neg(agx_fmov(b, agx_neg(wx)))),
agx_fmul_to(b, out, wx, wx));
CASE32(agx_fmul_to(b, out, wx, agx_neg(agx_fmov(b, agx_neg(agx_abs(wx))))),
agx_fmul_to(b, out, wx, agx_abs(wx)));
}
Fairly simple: CASE32 takes an input source, and compares it to the expected output source. For example, this one just fuses double negatives in floating-point arithmetic. As a side note, those instruction builder functions (e.g., agx_abs) are actually generated with agx_builder.h.py, so for reference, this is how I configured the build:
meson configure -Dvulkan-drivers="" -Dgallium-drivers="asahi" -Dtools="drm-shim,asahi" -Dbuild-tests="true" -Dglx="disabled" build/
Now I can write my first little test case:
TEST_F(Optimizer, FusedCmpsel)
{
CASE32(
{
wx.type = AGX_INDEX_UNIFORM;
wy.type = AGX_INDEX_UNIFORM;
agx_index tmp = agx_temp(b->shader, AGX_SIZE_32);
agx_fcmpsel_to(b, tmp, wx, wy, agx_immediate(0), agx_immediate(1),
AGX_FCOND_LT);
agx_icmpsel_to(b, out, tmp, agx_immediate(0), wy, wz, AGX_ICOND_UEQ);
},
{ agx_fcmpsel_to(b, out, wx, wy, wz, wy, AGX_FCOND_LT); });
}
One particular thing to note is that the ne condition of icmpsel.ne can be set up in two ways. Either src2 and src3 can be swapped, or the agx_instr::invert_cond flag can be set. I don’t actually see much usage of invert_cond, and in fact the AGX opcodes emitted (when NIR bcsel is encountered) use the former method, where the last two sources are swapped.
We should also add a case for icmpsel too:
TEST_F(Optimizer, FusedCmpsel)
{
CASE32(/* ... */);
CASE32(
{
wx.type = AGX_INDEX_UNIFORM;
wy.type = AGX_INDEX_UNIFORM;
agx_index tmp = agx_temp(b->shader, AGX_SIZE_32);
agx_icmpsel_to(b, tmp, wx, wy, agx_immediate(0), agx_immediate(1),
AGX_ICOND_ULT);
agx_icmpsel_to(b, out, tmp, agx_immediate(0), wy, wz, AGX_ICOND_UEQ);
},
{ agx_icmpsel_to(b, out, wx, wy, wz, wy, AGX_ICOND_ULT); });
}
We’re forcing wx and wy to be uniform so that we can test one of our first heuristics.
Optimizing
This is the fun part - where we actually write the code that optimizes these instructions. Before we can do that however, we should pick out the heuristics we’re going to use. Ideally I want to only implement either a forward pass or backwards pass. This fact simplifies things a bit when it comes to deciding which heuristics to use, as we’ll just use the heuristics that perform best when they’re a part of the forward or backwards pass.
For the forward pass heuristics, we could:
- Heuristic 1: Fuse when
aandbare constant/uniform (i.e., in the SGPR)
For the backward pass heuristics, we could:
- Heuristic 2: Fuse when the
bool(from the firstcmpsel) is only used by the secondicmpsel - Heuristic 3: Fuse when
canddare constant/uniform
Now let’s analyse the cost (that is, the effect on register pressure) of each of these heuristics. For each scenario, I’ll make the assumption that we’re in the best case and the cmpsels are the only users of values a to d, and bool. We’ll also ignore the pressure of dest since that’s always going to be there. Just as a side note, I’m using my own little made-up metric of RP to indicate arbitrary units of register pressure, per value.
For Heuristic 1:
The source IR…
# const a, b
fcmpsel bool, a, b, 0, 1 # RP = +1 (bool)
# ...
icmpsel.ne dest, bool, 0, c, d # RP = +3 (c + d + bool)
Optimizes into:
# const a, b
fcmpsel bool, a, b, 0, 1 # RP = +1 (bool) << DCE?
# ...
fcmpsel dest, a, b, c, d # RP = +2 (c + d)
This scenario gives us a clear win, since we can eliminate the first fcmpsel in many cases, and don’t need to keep around bool as a result either. The peak register pressure also ends up being lower assuming nothing needs to use bool besides other cmpsels - or if they do, bool hopefully don’t need to live as long and can be killed off earlier thanks to this heuristic. I’ll give this heuristic the thumbs up!
For Heuristic 2:
The source IR…
fcmpsel bool, a, b, 0, 1 # RP = +3 (a + b + bool)
# ...
icmpsel.ne dest, bool, 0, c, d # RP = +3 (c + d + bool)
Optimizes into:
fcmpsel dest, a, b, c, d # RP = +4 (a + b + c + d)
This heuristic seems to be a bit hit or miss. In the absolute worst case scenario, as shown above, if a and b are killed by fcmpsel, and c and d are killed by icmpsel but the lifetime of both pairs is mutually exclusive, then we actually end up with a greater peak register pressure since we now need a, b, c, and d all alive at the same time. For now, I’ll give this a “meh” rating. How well this heuristic performs depends entirely upon the shader. On a side note, this is why it’s worthwhile to test our heuristics on something like shader-db; so that we can get a more practical real-world analysis.
For Heuristic 3:
The source IR…
# const c, d
fcmpsel bool, a, b, 0, 1 # RP = +3 (a + b + bool)
# ...
icmpsel.ne dest, bool, 0, c, d # RP = +3 (c + d + bool)
Optimizes into…
# const c, d
fcmpsel dest, a, b, c, d # RP = +2 (a + b)
# ...
icmpsel.ne dest, bool, 0, c, d # RP = +3 (a + b + bool) << DCE?
This is just the inverse case of heuristic 1, and I can also safely give this a thumbs up.
One last heuristic mentioned in the original issue that I didn’t bring up - I’ll label it heuristic 4 - is to forward fuse unconditionally. Let’s see how that would turn out:
fcmpsel bool, a, b, 0, 1 # RP = +3 (a + b + bool)
# ...
icmpsel.ne dest, bool, 0, c, d # RP = +3 (c + d + bool)
Optimizes into…
fcmpsel bool, a, b, 0, 1 # RP = +3 (a + b + bool)
# ...
fcmpsel dest, a, b, c, d # RP = +4 (a + b + c + d)
This is like heuristic 2, but really with none of the benefit. This heuristic doesn’t operate under the condition that the icmpsel is the only user of bool: For all we know, the register pressure here could even peak at RP = +5.
Writing
All of those heuristics may reduce register pressure, or they may increase it, or their conditions may be too strict to be useful. Now the only way to find out is to actually run them on real shaders. Even before we can do that, we actually need to write the optimizer!
The function signature for forward optimizers tells us everything about what we need to do:
/* Heuristic 1 */
static void
agx_optimizer_cmpsel_h1(agx_instr **defs, agx_instr *I)
{
/* TODO */
}
defs is an array of all the instructions, and I is the instruction we’re currently optimizing. For all the forward heuristics, we need to first check if it actually is a case of fcmpsel bool, a, b, 0, 1 -> icmpsel.ne dest, bool, 0, c, d.
/* Heuristic 1 */
static void
agx_optimizer_cmpsel_h1(agx_instr **defs, agx_instr *I)
{
/* icmpsel.eq */
if (I->op != AGX_OPCODE_ICMPSEL || I->icond != AGX_ICOND_UEQ)
return;
/* 2nd src equals 0 */
if (I->src[1].type != AGX_INDEX_IMMEDIATE || I->src[1].value != 0)
return;
/* 1st src is ssa */
if (I->src[0].type != AGX_INDEX_NORMAL)
return;
/* the instruction that wrote the 1st src */
agx_instr *def = defs[I->src[0].value];
/* 1st src was not written by cmpsel */
if (def->op != AGX_OPCODE_FCMPSEL && def->op != AGX_OPCODE_ICMPSEL)
return;
/* the def cmpsel did not select between 0 and 1 */
if (def->src[2].type != AGX_INDEX_IMMEDIATE ||
def->src[2].value != 0 ||
def->src[3].type != AGX_INDEX_IMMEDIATE ||
def->src[3].value != 1)
return;
/*
done! if we reach this point, we are 100% certain that we are dealing with
our specific case of two cmpsels.
*/
}
For heuristic 1 in particular, we need to also confirm that a and b are uniform values:
/* Heuristic 1 */
static void
agx_optimizer_cmpsel_h1(agx_instr **defs, agx_instr *I)
{
/* ... */
/* confirm first two srcs are uniform */
if (def->src[0].type != AGX_INDEX_UNIFORM ||
def->src[1].type != AGX_INDEX_UNIFORM)
return;
}
Once we confirm everything, it’s a simple case of swapping out the opcode and operands:
/* Heuristic 1 */
static void
agx_optimizer_cmpsel_h1(agx_instr **defs, agx_instr *I)
{
/* ... */
/* replace opcode */
I->op = def->op;
if (I->op == AGX_OPCODE_FCMPSEL)
I->fcond = def->fcond;
else if (I->op == AGX_OPCODE_ICMPSEL)
I->icond = def->icond;
/* set first two operands from the def */
I->src[0] = def->src[0];
I->src[1] = def->src[1];
/* swap last two operands: eq -> neq */
if (!I->invert_cond) {
agx_index tmp = I->src[2];
I->src[2] = I->src[3];
I->src[3] = tmp;
}
}
It’s at this point I realize that heuristic 2 would not be trivial to implement. The backwards pass only keeps track of the last use of a def and whether it has multiple uses. It never tracks all of the uses of a def. By the time we arrive to the first cmpsel that defs bool, we can only fuse one subsequent icmpsel.ne and thus it would not converge in a single iteration. It would be possible to restructure how uses are tracked in the backwards optimizer, but that’s already creeping well out of the scope of my patch and, doubly, it would cost much more memory to track.
Anyway, I won’t bore you with the code, but in short, we can implement heuristic 4 by taking heuristic 1 and removing the check to see if a and b are uniform, and heuristic 3 is just heuristic 1 but written as a backwards pass.
With that done, now we just need to test each one on real-world shaders, to see which one performs best overall.
The following section was written on 2024-04-14.
Retrospective
So, I never did end up testing the code, or pushing it, or merging it into Mesa. Partially this is because I had other commitments, but also partially because the process involved in getting shader-db up and running was lost on me.
Randomly though, this little project did pop into my head 8 months later, and I went back to the Mesa issue tracker to check if the issue was still open – It was closed. I dug around and indeed the cmpsel fuse optimizer was in-branch, committed by Alyssa.
From what I can tell, it seems like heuristic 4 was chosen: Fuse forward unconditionally. For fun, let’s compare my code to the code in-branch:
Alyssa’s code
static void
agx_optimizer_cmpsel(agx_instr **defs, agx_instr *I)
{
if (!agx_is_equiv(I->src[1], agx_zero()) || I->icond != AGX_ICOND_UEQ ||
I->src[0].type != AGX_INDEX_NORMAL)
return;
// same thing but concise!
agx_instr *def = defs[I->src[0].value];
if (def->op != AGX_OPCODE_ICMP && def->op != AGX_OPCODE_FCMP)
return;
// ???
I->src[0] = def->src[0];
I->src[1] = def->src[1];
if (!def->invert_cond) {
agx_index temp = I->src[2];
I->src[2] = I->src[3];
I->src[3] = temp;
}
if (def->op == AGX_OPCODE_ICMP) {
I->op = AGX_OPCODE_ICMPSEL;
I->icond = def->icond;
} else {
I->op = AGX_OPCODE_FCMPSEL;
I->fcond = def->fcond;
}
}
My code
static void
agx_optimizer_cmpsel(agx_instr **defs, agx_instr *I)
{
if (I->op != AGX_OPCODE_ICMPSEL || I->icond != AGX_ICOND_UEQ)
return;
if (I->src[1].type != AGX_INDEX_IMMEDIATE || I->src[1].value != 0)
return;
if (I->src[0].type != AGX_INDEX_NORMAL)
return;
agx_instr *def = defs[I->src[0].value];
if (def->op != AGX_OPCODE_FCMPSEL && def->op != AGX_OPCODE_ICMPSEL)
return;
if (def->src[2].type != AGX_INDEX_IMMEDIATE || def->src[2].value != 0 ||
def->src[3].type != AGX_INDEX_IMMEDIATE || def->src[3].value != 1)
return;
I->src[0] = def->src[0];
I->src[1] = def->src[1];
if (!I->invert_cond) {
agx_index tmp = I->src[2];
I->src[2] = I->src[3];
I->src[3] = tmp;
}
I->op = def->op;
if (I->op == AGX_OPCODE_FCMPSEL)
I->fcond = def->fcond;
else if (I->op == AGX_OPCODE_ICMPSEL)
I->icond = def->icond;
}
In general, I’m happy that I got a lot of things right (though admittedly it’s not a lot of code). Clearly I missed some helpers to make the first few guards to the optimization far more concise, and I really have no idea what I was trying to do by checking if def had immediate operands, but otherwise the rest matches up pretty well!
So evidently this wasn’t a complete waste of time - at least I was able to come back to it, and it was definitely an interesting foray into this side of the graphics stack.